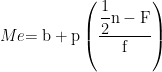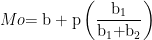Distribusi peluang kontinu adalah peubah acak yang dapat memperoleh semua nilai pada skala
. Ruang sampel kontinu adalah bila ruang sampel mengandung titik sampel yang tak terhingga
banyaknya. Syarat dari distribusi kontinu adalah apabila fungsi f(x) adalah fungsi padat peluang
peubah acak kontinu X yang didefinisikan di atas himpunan semua bilangan riil R bila:
1. F(x) ≥ 0 untuk semua x є R
2. ∫𝑓(𝑥)𝑑𝑥=1∞∞
3. 𝑃(𝑎<𝑋<𝑏)= ∫𝑓(𝑥)𝑑𝑥
B. Konsep dan Teorema Distribusi
1.Distribusi Normal
Distribusi Normal (Gaussian) mungkin merupakan distribusi probabilitas yang paling penting
baik dalam teori maupun aplikasi statistik. Distribusi ini paling banyak digunakan sebagai model
bagi data riil di berbagai bidang yang meliputi antara lain karakteristik fisik makhluk hidup
(berat, tinggi badan manusia, hewan, dll). Terdapat empat alasan mengapa distribusi normal
menjadi distribusi yang paling penting :
a. Distribusi normal terjadi secara alamiah.
b. Beberapa variabel acak yang tidak terdistribusi secara normal dapat dengan mudah
ditransformasi menjadi suatu distribusi variabel acak yang normal.
c. Banyak hasil dan teknik analisis yang berguna dalam pekerjaan statistik hanya bisa
berfungsi dengan benar jika model distribusinya merupakan distribusi normal.
d. Ada beberapa variabel acak yang tidak menunjukkan distribusi normal pada populasinya,
namun distribusi dari rata-rata sampel yang diambil secara random dari populasi tersebut
ternyata menunjukkan distribusi normal.
Distribusi Normal disebut juga Gausian distribution adalah salah satu fungsi distribusi
peluang
berbentuk lonceng seperti gambar berikut.

Berdasarkan gambar di atas, distribusi Normal akan memiliki beberapa ciri diantaranya:
a. Kurvanya berbentuk garis lengkung yang halus dan berbentuk seperti genta.
b. Simetris terhadap rataan (mean).
c. Kedua ekor/ ujungnya semakin mendekati sumbu absisnya tetapi tidak pernah maemotong.
d. Jarak titik belok kurva tersebut dengan sumbu simetrisnya sama dengan σ
e. Luas daerah di bawah lengkungan kurva tersebut dari - ~ sampai + ~ sama dengan 1 atau
100 %.
Sebuah variabel acak kontinu X dikatakan memiliki distribusi normal dengan parameter 𝜇𝑥
dan 𝜎𝑥 dimana −∞<𝜇𝑥<∞ dan 𝜎𝑥>0 jika fungsi kepadatan probabilitas dari X adalah
𝑓𝑁(𝑥;𝜇𝑥,𝜎𝑥)=1𝜎𝑥√2𝜋𝑒−(𝑥−𝜇𝑥)2(2𝜎𝑥2) , −∞<𝑥<∞ ........................ (1)
Dimana :
𝜇𝑥 = mean
𝜎𝑥 = deviasi standard
𝜋 = nilai konstan yaitu 3, 1416
𝑒= nilai konstan yaitu 2,7183
Untuk setiap nilai 𝜇𝑥 dan 𝜎𝑥, kurva fungsi akan simetris terhadap 𝜇𝑥 dan memiliki total luas
dibawah kurva tepat 1. Nilai dari 𝜎𝑥 menentukan bentangan dari kurva sedangkan 𝜇𝑥 menentukan
pusat simetrisnya.
Distribusi normal kumulatif didefinisikan sebagai probabilitas variabel acak normal X bernilai
kurang dari atau sama dengan suatu nilai x tertentu. Maka fungsi distribusi kumulatif dari distribusi
normal ini dinyatakan sebagai :
𝑓𝑁(𝑥;𝜇𝑥,𝜎𝑥)=𝑃(𝑋≤𝑥)=∫𝑓𝑁(𝑡;𝜇𝑥,𝜎𝑥)𝑑𝑡=∫1𝜎𝑥√2𝜋𝑒(𝑡−𝜇𝑥)2(2𝜎𝑥2)𝑑𝑡𝑥−∞𝑥−∞ ..............(2)
Untuk menghitung probabilitas 𝑃(𝑎≤𝑥≤𝑏) dari suatu variabel acak kontinu X yang
terdistribusi secara normal dengan parameter 𝜇𝑥 dan 𝜎𝑥 maka persamaan (1) harus diintegralkan
mulai dari 𝑥=𝑎 sampai 𝑥=𝑏. Namun, tidak ada satupun dari teknik-teknik pengintegralan biasa yang
bisa digunakan untuk menentukan integral tersebut. Untuk itu para ahli statistik/matematik telah
membuat sebuah penyederhanaan dengan memperkenalkan sebuah fungsi kepadatan probabilitas
normal khusus dengan nilai mean 𝜇=0 dan deviasi standard 𝜎=1. Distribusi ini dikenal sebagai
distribusi normal standard (standard normal distribution). Variabel acak dari distribusi normal
standard ini biasanya dinotasikan dengan Z.
Dengan menerapkan ketentuan diatas pada persamaan (1) maka fungsi kepadatan probabilitas
dari distribusi normal standard variabel acak kontinu Z adalah:
𝑓𝑁(𝑧;0,1)=1√2𝜋𝑒−𝑧22 , −∞<𝑧<∞ ......................................................(3)
Sedangkan fungsi distribusi kumulatif dari distribusi normal standard ini dinyatakan sebagai :
𝑓𝑁(𝑧;0,1)=𝑃(𝑍≤𝑧)=Φ(𝑧)=∫1√2𝜋𝑒−𝑡22𝑑𝑡𝑧−∞ ..................................(4)
Distribusi normal variabel acak kontinu X dengan nilai-nilai parameter 𝜇𝑥 dan 𝜎𝑥 berapapun
dapat diubah menjadi distribusi normal kumulatif standard jika variabel acak standard Zx menurut
hubungan :
𝑧𝑥=𝑥−𝜇𝑥𝜎𝑥
Nilai 𝑧𝑥 dari variabel acak standard 𝑧𝑥 sering juga disebut sebagai skor z dari variabel acak X.
2. Distribusi Chi-Kuadrat (𝝌𝟐)
Distribusi chi-kuadrat merupakan distribusi yang banyak digunakan dalam sejumlah prosedur statistik inferensial. Distribusi chi-kuadrat merupakan kasus khusus dari distribusi gamma dengan faktor bentuk 𝛼=𝑣/2, dimana v adalah bilangan bulat positif dan faktor skala 𝛽=2.
Jika variabel acak kontinu X memiliki distribusi chi-kudrat dengan parameter v, maka fungsi kepadatan probabilitas dari X adalah :
𝑓𝜒2(𝑥;𝑣)={12𝑣2Γ(𝑣2)𝑥(𝑣2)−1𝑒−𝑥2 𝑥≥0 0 𝑦𝑎𝑛𝑔 𝑙𝑎𝑖𝑛
Parameter n disebut angka derajat kebebasan (degree of freedom/df) dari X. Sedangkan
fungsi distribusi kumulatif chi-kuadrat adalah :
𝑓𝜒2(𝑥;𝑣)=𝑃(𝑋≤𝑥)=∫12𝑣2Γ(𝑣2)𝑡(𝑣2)−1𝑒−𝑡2 𝑥0𝑑𝑡
Berikut ini diberikan rumusan beberapa ukuran statistik deskriptif untuk distribusi chi
kuadrat.
Mean (Nilai Harapan) :
𝜇𝑥=𝐸( )=𝑣
Varians :
𝜎𝑥2=2𝑣
Kemencengan (skewness) :
𝛽1=𝛼32=8𝑣
Keruncingan (kurtosis) :
𝛽2=𝛼4=3(4𝑣+1)
Contoh :
Suatu perusahaan baterai mobil memberikan jaminan bahwa masa pakai baterai yang
diproduksinya adalah rata-rata 3 tahun dengan simpangan baku 1 tahun. Jika diambil contoh
sebanyak 5 buah baterai dan masa pakainya (dalam tahun) adalah: 1,9 ; 2,4 ; 3,0 ; 3,5 ; dan 4,2.
Apakah benar bahwa jaminan perusahaan tentang simpangan baku 1 tahun dapat dipercaya?
Penyelesaian :
Pertama-tama kita menghitung nilai ragam contoh (𝑠2) :
𝑠2=48,26−(15)255−1=0,815 𝑋2=(𝑛 −1)𝑠2𝜎2=(4)(0,815)1=3,26
Nilai 3,26 adalah nilai chi kuadrat dengn derajat bebas v = n-1 = 5-1 =4. Karena 95% dari
nilai chi kuadrat dengan derajat bebas 4 terletak antara 0,484 (𝑋0,0252) dan 11,1 (𝑋0,9752)
Maka berdasarkan nilai 𝑋2=3,26 terletak dalam selang nilai sebaran chi kuadrat 95% dengan derajat bebas 4, maka pernyataan bahwa simpangan baku adalah 1 tahun masih dapat dipercaya.
4. Distribusi F
Menurut Gasperz (1989:251), secara teori sebaran F merupakan rasio dari dua sebaran chi kuadrat yang bebas. Oleh karena itu peubah acak F diberikan sebagai: 𝐹=𝑋12𝑉1⁄𝑋22𝑉2⁄
Dimana : 𝑋12= 𝑛𝑖𝑙𝑎𝑖 𝑑𝑎𝑟𝑖 𝑠𝑒𝑏𝑎𝑟𝑎𝑛 𝑐ℎ𝑖 𝑘𝑢𝑎𝑑𝑟𝑎𝑡 𝑑𝑒𝑛𝑔𝑎𝑛 𝑑𝑒𝑟𝑎𝑗𝑎𝑡 𝑏𝑒𝑏𝑎𝑠 𝑉1=𝑛1−1 𝑋22= 𝑛𝑖𝑙𝑎𝑖 𝑑𝑎𝑟𝑖 𝑠𝑒𝑏𝑎𝑟𝑎𝑛 𝑐ℎ𝑖 𝑘𝑢𝑎𝑑𝑟𝑎𝑡 𝑑𝑒𝑛𝑔𝑎𝑛 𝑑𝑒𝑟𝑎𝑗𝑎𝑡 𝑏𝑒𝑏𝑎𝑠 𝑉2=𝑛2−1
Oleh karena itu sebaran F mempunyai dua derajat bebas yaitu 𝑉1 𝑑𝑎𝑛 𝑉2.
Misal :
Kita ingin mengetahui nilai F dengan derajat bebas 𝑉1=10 dan 𝑉2=12, maka jika 𝛼=0,05 dari tabel F diperoleh nilai 𝐹0,05 (10,12)=2,75